3 Lessons from Building a 170GB Iceberg Lakehouse with 8GB RAM
Unifying heterogeneous marketplace feeds into one Iceberg medallion lakehouse on a single server.
On this page
Evan Kim · June 2026
TL;DR
3 lessons from a 170GB object store, 9 production pipelines, and 10+ marketplace labels on 1 server with an 8GB writer memory cap:
- Coordinate heterogeneous ingest paths with a lane registry and schema contracts so 9 writers converge on 1 gold model.
- Incremental gold on Iceberg: each gold table commits atomically and serves snapshot-consistent reads, so the API never sees a half-written merge while sources write continuously.
- Heavy work takes turns on 1 machine—ingest and promotion never run at full blast together—so each step's working set stays within the 8GB writer cap.
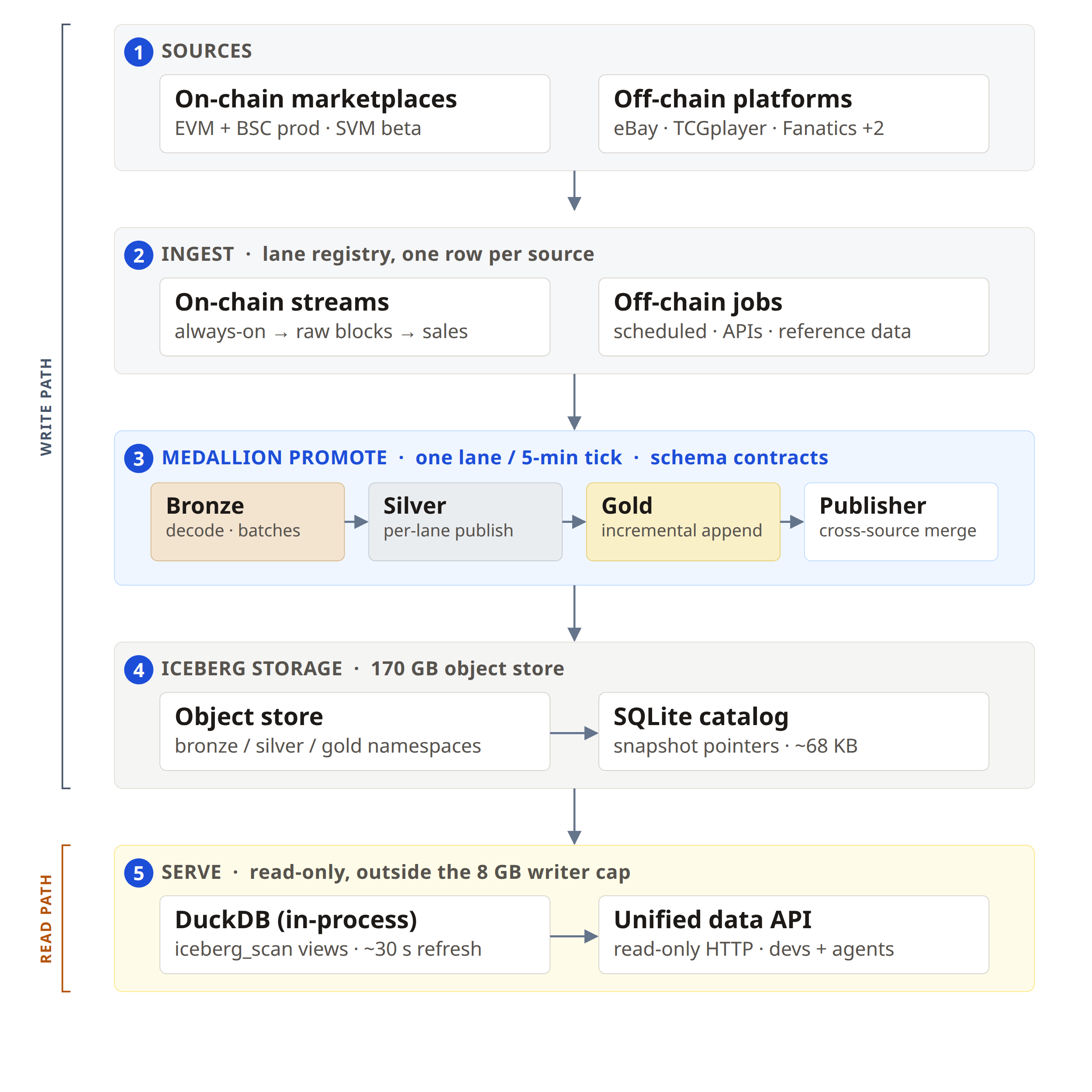
I build and maintain an analytics lakehouse for Pokémon TCG—around 170GB of object storage, served through a single read-only API. The constraint that shapes every decision below: ingestion and promotion run on 1 server, sharing an 8GB writer memory cap.
The hard part is the variety of what feeds it. Pokémon cards trade across 2 very different worlds. On-chain, sales settle on blockchains—EVM and BSC marketplaces in production, plus Solana (SVM) in beta. Off-chain, the same cards sell on the major platforms—eBay, TCGPlayer, Fanatics, Alt, Mercari. No 2 sources share a row shape, a cadence, or the same idea of what a "sale" is.
What feeds the lakehouse
The heterogeneous variety creates a complex write surface: 9 production pipelines today, each with its own cadence and row shape.
- 4 always-on EVM marketplace streams (log ingestion and sale reconstruction)
- 1 always-on BSC marketplace stream (same promote machinery, separate chain-family row in the registry)
- 3 scheduled off-chain ingests (scraping auction sold-comps—historical sold prices—plus retailer/marketplace APIs and grading/population reference tables)
- 1 cross-source gold publisher (unified sales, price history, card rollups)
9 writers feed 1 API surface, so every pipeline converges on the same card identifier, sale schema, and freshness expectations on the way to gold. Those tiers are the medallion pattern: raw ingested rows land in bronze, get cleaned and typed into silver, then merge across all sources into the gold tables the API serves. Promotion is the scheduled step that advances 1 source's data up those tiers and commits the result, 1 lane at a time. That machinery plus the lane registry carries the convergence on a single box.
The read side is simpler: 1 unified data API over DuckDB on Iceberg, aimed at developers and agents querying the same gold tables. The rest of this post is about the write path that feeds it.
Lesson 1
1 registry row per source keeps promotion wired.
The problem. 9 writers, no 2 alike: EVM and BSC logs, Solana program events, and a handful of off-chain scraper formats all have to land in the same gold tables under the same card IDs, sale schema, and freshness contract. Wire each source by hand and every new marketplace becomes its own bespoke pipeline—and the charts fracture the first time 2 venues spell the same brand differently.
The fix. Push everything that differs between sources into 1 declared row, and let shared machinery read that row. That table is the lane registry: 1 row—1 lane—per marketplace source, where the row declares the source's chain family (EVM, BSC, or SVM), ingest mode, curation strategy, and which silver and gold tables it feeds. Promote, silver publish, and incremental gold all iterate this single table. Adding a source means adding a row plus a curator—the small per-source plugin that parses that marketplace's raw format into the shared schema.
The registry handles coordination; the per-source logic stays in those curator plugins. EVM and BSC lanes mostly share transfer-and-join reconstruction, with individual venues adding marketplace-specific parsers where the default breaks. SVM lanes route to program-instruction curators because a Solana event looks nothing like an EVM log. Off-chain scrapers emit their own envelopes. Everything outside that parsing—promote order, silver table, gold chunk key—is declared in the row, not written in code.
That split solves the coordination problem: 9 unlike writers need 1 place that says what runs, where it lands, and which gold tables it feeds. Promote, silver publish, and incremental gold all read the same row, so adding a marketplace means writing a curator and declaring a row, not standing up a new pipeline. SVM beta lanes already follow that path.
Standardization on top of the registry
The registry answers which plugin runs. Schema contracts answer what shape comes out:
- Shared sale schema at gold because every lane must normalize into 1 typed contract before cross-venue tables are built; publish fails closed on column drift
- Marketplace label bucketing because raw venue strings from APIs fracture charts; several variants of the same brand collapse to 1 label at serve time
- Card ID aliasing because upstream identifiers differ by venue; gold joins run on a canonical catalog ID
- Language and grade normalization because venues emit "English" and "en" interchangeably; query filters need 1 enum
The lesson. This unglamorous work is what makes the lakehouse queryable across marketplaces. Because promote, silver, and gold are already wired through the registry, a new source is mostly a week of curator work rather than a new pipeline. The registry row is what keeps that promotion wired with no bespoke glue per source.
Lane registry row
→ ingest (stream or scheduled job)
→ curation plugin for that row's strategy
→ silver publish (table name from registry)
→ incremental gold chunk (key from registry)
→ unified cross-venue tablesLesson 2
Iceberg pays off on incremental, multi-namespace gold.
The problem. 3 things happen at once on 1 machine: sources commit continuously, gold advances 1 lane at a time, and the API must serve a consistent snapshot while promotion is mid-tick.
The fix. Iceberg's incremental commits and snapshot isolation carry all 3. Here is what the stack leans on:
What the stack leans on
- Medallion namespaces for per-lane bronze, a conformed silver layer, and gold cross-venue facts
- Incremental gold writes because each promote tick commits 1 lane's bounded delta into the shared sales tables—an append where rows are immutable, a keyed upsert where they revise—never a full reload of the object store
- SQLite catalog because a single writer process plus a local catalog file make the metadata-pointer swap atomic with zero extra infrastructure; it is safe precisely because nothing else writes it
- Snapshot-consistent API reads because the API resolves each gold table's current metadata pointer from the catalog and points DuckDB at it; every query then reads 1 committed snapshot, untouched by an in-flight promote
- Watermarks committed with the data because each promote writes its high-water mark in the same atomic commit as the rows it advances; PyIceberg has no incremental snapshot scan, so that watermark is what lets the next tick read only the new delta
Cross-source dedup and sale-priority rules live in the gold publisher. Each gold table commits atomically on its own metadata pointer, so a reader sees a table either before or after a merge, never mid-write. Iceberg's atomicity is per-table, not across tables, so a tick advances the gold set table by table rather than in 1 cross-table transaction—the API tolerates a partially advanced tick by design.
Production scar tissue: courtyard silver
The heaviest lane taught us what "incremental" actually has to mean on an 8GB box. Courtyard silver holds about 8.4M rows. Before the fixes below, promote ticks on that lane routinely died before finishing:
- 6.6GB RSS on silver publish, killed mid-tick
- ~7GB on the first post-outage tick when PyIceberg upsert fell back to copy-on-write over nearly all existing silver files
- ~5GB reading wide
CourtyardTradeExecutedcolumns when the curate step only needed 4 of them
Each failure blocked gold from advancing—not because gold merge logic was wrong, but because silver never finished committing. The fixes were all write-shape changes on the path to gold:
- Column projection + streaming read on the trade-executed LUT: ~5GB → ~1.5GB peak
- Partition overwrite instead of upsert on EVM silver (append-only bronze makes this safe)
- Generator day-bucket chunking instead of materializing every bucket at once: estimated 6.6GB → <1GB on bootstrap
- Shorter per-lane timeout for courtyard, with an option to skip it from stagger while backlog exists
That is why Lesson 2 is not "use Iceberg." It is: incremental commits and snapshot isolation only pay off once every layer writes bounded deltas—and gold can trust that silver actually landed.
Serving
At startup the API resolves each gold table's current metadata location from the catalog and registers a DuckDB iceberg_scan view over it. DuckDB itself does not watch the catalog, so about every 30 seconds the API re-resolves those pointers and re-registers any view whose snapshot advanced, then runs SQL joins in process. The product surface is the committed gold tables the catalog points at—a queryable subset of the 170GB bucket.
The lesson. Because each table commit is atomic and every query reads 1 committed snapshot, the API serves a coherent gold version even while a lane is mid-promotion. That is where Iceberg pays off on incremental, multi-namespace gold—and why serving is the easy half once gold is trustworthy.
Lesson 3
On 1 machine, scale means backpressure.
The problem. 1 machine, 8GB of memory for every writer, and 170GB of data that won't fit in RAM many times over. Let ingestion and promotion run freely and 2 heavy stages eventually overlap, the box hits its memory ceiling, and a writer dies mid-commit. On a single server you can't scale out of this—you can only scale the work down to fit.
The fix. Bound every stage and serialize the heavy work so only 1 lane is ever in flight:
- Staggered promotion: 1 lane per timer tick
- Capped decode batches per tick, with adaptive shrinkage under memory pressure
- Chunked curated rebuilds for the heaviest lanes
- Analytics in a subprocess so decode/curate memory is released before the next stage
- A filesystem lock so daily scrapes and long jobs take turns with promote
- An 8GB writer cgroup; the API process sits outside it
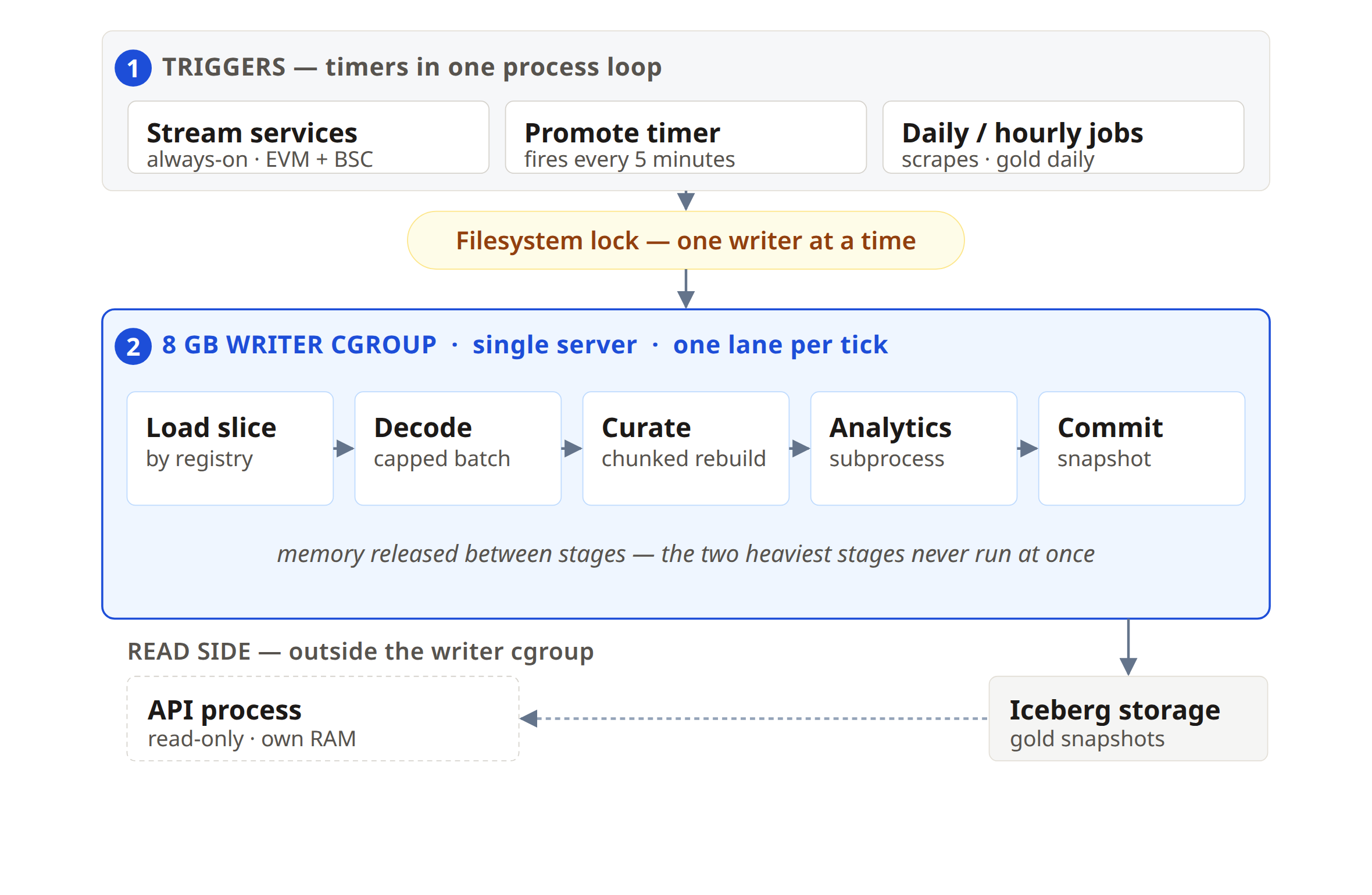
A handful of timers and 1 promote state machine carry the dependency graph in a single process loop, which keeps the ops surface small on a side-project budget.
The lesson. Each tick loads only the current lane's bounded slice—tens of GB at most, never the whole store—and commits through Iceberg when the stage finishes, so the writer's working set stays inside the 8GB cap no matter how large the table on disk grows. On 1 box, scale isn't about going bigger; it's backpressure—making sure the 2 heaviest things never run at once.
Takeaway
This is production Iceberg as a convergence and concurrency tool on a budget box: lane registry, schema contracts, incremental gold, memory-bounded promotion—DuckDB serving once gold is trustworthy.
A second lesson sits underneath the architecture: agent-built infrastructure needs the same discipline as the data it moves. Subagents wrote the registry rows, curators, and promote paths—but what kept the design from drifting across sessions was a shared Apache Iceberg lakehouse skill. It pinned the decisions that have to stay fixed: watermarks, bounded aggregate shapes, owned maintenance. Without it, each agent reinvents the lakehouse from scratch, and the contracts that hold 9 writers on the same gold tables quietly come apart.